From Agent Demos to Autonomous Systems: The Execution Gap Enterprises Aren’t Ready For
Bob Tinker
Co-Founder & Former CEO, BlueRock Board Member
56% of enterprises already have AI agents in production, but the real power of agentic has yet to be unlocked.
Wing VC published a stat this month that should make every engineering, devops and security leader pause: 56% of large enterprises are already in early or large-scale production for AI agents. (Wing Venture Capital)
That’s the part everyone repeats.
The more important part is what it implies: we’re moving from “build a cool agent demo” to operate agentic systems as real software that takes autonomous action. And for a lot of teams, MCP (Model Context Protocol) is becoming the default way agents talk to tools and systems. (Which is great. Standard protocols are how ecosystems scale.)
But here’s the uncomfortable truth I keep seeing in real deployments:
We’re learning how to build and deploy agents—often read-only and human-in-the-loop. The hard part is getting inside them to troubleshoot to success, and guardrail them to keep them on the rails.
Agents are crossing the production threshold. This unlocks massive business ROI. It also creates real operational and security challenges.
Agentic has crossed the production threshold. Pilots don’t prepare you for what happens next.
Agentic has crossed the production threshold. Pilots don’t prepare you for what happens next.
Wing’s report isn’t hype. It’s grounded in what chief-level leaders are reporting across the enterprise landscape: a median expectation that 50% of AI pilots will convert to production, and a meaningful portion of large enterprises already seeing ROI.
A few data points worth holding in your head as you plan for 2026 (Source: Wing Venture Capital):
56% of large enterprises are in early or large-scale production for AI agents.
67% are using agent/orchestration frameworks (meaning agents aren’t a side-project anymore; they’re becoming platformized).
68% of large enterprises report positive ROI from at least one AI use case.
Top blockers are still painfully familiar: integration with existing systems (~50%) and data (~49%).
87% of CTOs report measurable developer productivity gains from AI dev tools, copilots, and agents.
But pilots have a convenient property: they can “work” while avoiding the hardest questions. In pilots, the agent:
Uses a small toolset
Touches safe data
Runs slowly, with a human supervising
Lives in an environment where “oops” is survivable
Production breaks those assumptions. Real agents need real tools. Real tools touch real systems. Real tools take real action. And the moment you chain tools together, the system stops behaving like a chatbot and starts behaving like a powerful (semi) autonomous system.
That’s where MCP shows up: it standardizes agent-to-tool interaction, makes tool integration easier, and makes agent ecosystems composable. Again: a good thing.
It also makes the next set of problems show up faster.
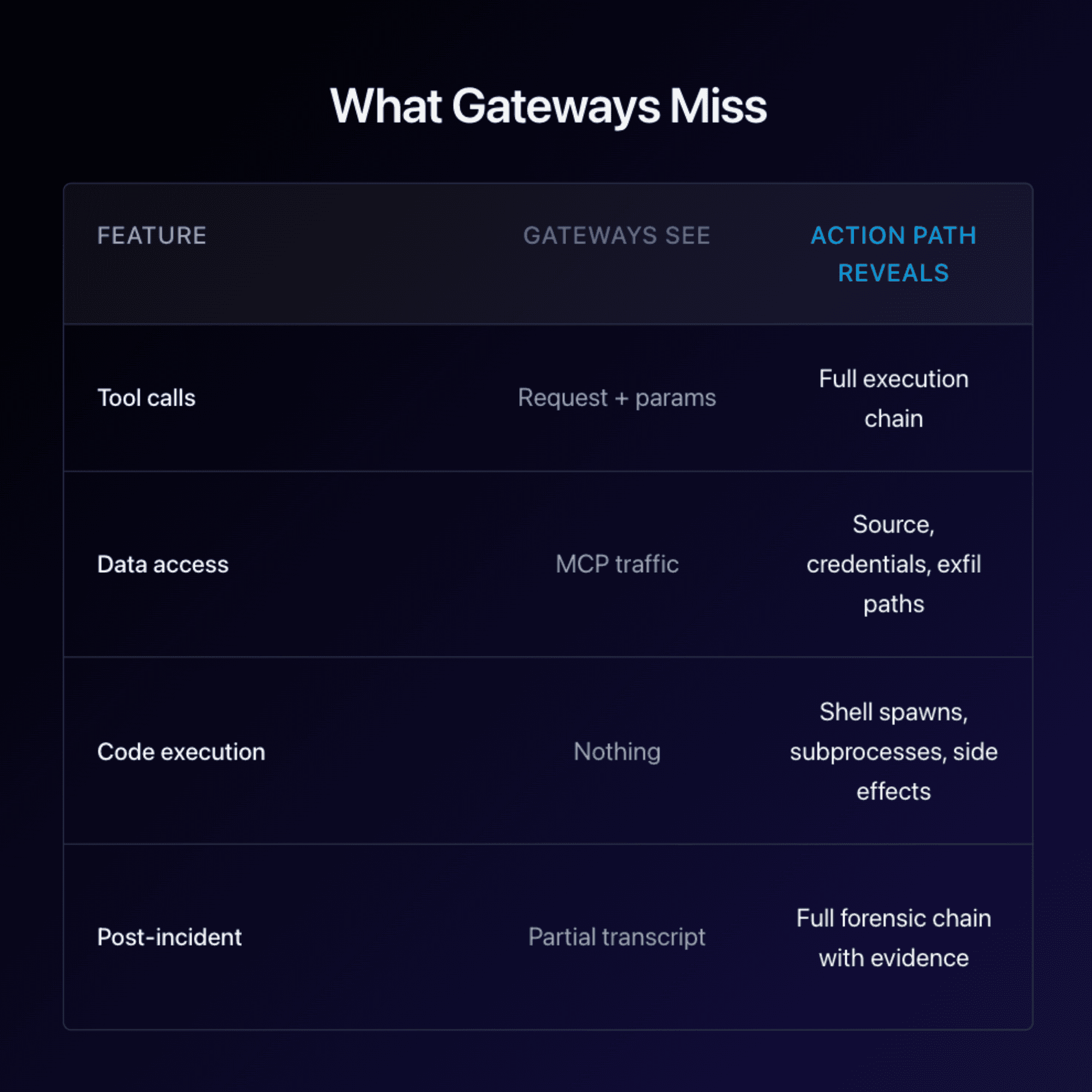
The “Agentic Action Path” problem: request and response are visible… everything between is a black box.
When an agent runs, you typically see the user request and you see the agent response. Everything in the middle—the actual work—is often opaque:
Agent → MCP Tools & Server → Data Resources
The Agentic Action Path
When an agent runs, you see the request. You see the response. Everything in between—the actual work—is the agentic action path: the chain of tool calls, data access, and code execution that produced the outcome.
Most teams can’t see it. That’s action-path blindness.
Because agentic systems have a few properties that traditional services don’t:
Non-determinism: the same prompt can lead to different tool chains
Emergent behavior: tool combinations produce outcomes nobody explicitly designed
Delegation: agents can invoke tools that invoke other tools (or spawn subprocesses)
Accountability gaps: “who did what?” becomes murky fast
Here’s a scenario I’ve seen in multiple flavors:
The invisible subprocess chain. An agent has access to multiple MCP servers. It calls a tool (“analyze_logs”). That tool shells out to run a helper script. The script pulls data from a location the team didn’t intend, using credentials available on the host. Then it writes a summary back to the agent.
Who saw that shell command? Who saw the data source? Who can reconstruct the chain after the fact?
In traditional enterprise systems, you’d expect logs, traces, policy checks, and least-privilege boundaries. In many agentic systems today, you get a neat tool-call transcript and very little else.
That’s the gap: tool invocation visibility is not execution visibility.
Five MCP challenges teams keep running into
These are the patterns I’d bet you’ll recognize if you’re past the demo stage.
1. Action-path blindness: you can’t debug what you can’t see
When an agent fails, the question isn’t “what did the model say?” It’s: Which tools did it call? With what parameters? What data was accessed or modified? What side effects happened downstream?
Without action-path observability, debugging becomes guesswork, and teams fall back to limiting agent autonomy—not because autonomy is bad, but because the system is un-operable.
The ‘why did it do that?’ incident. A deployment agent “helpfully” tries to remediate an error by rolling back a service. It calls
deploy.rollback(service=X). But inside the tool implementation, a config mismatch maps X to the wrong environment. Now prod is rolling back while the incident channel is reading a tool-call transcript that looks totally reasonable.
You don’t need fear-mongering to see the problem: without deep visibility into execution, small mismatches turn into outages.
2. Unvetted tools that can take real action
MCP makes it easy to connect to servers. That’s the point. The downside is equally obvious: developers or teams can connect agents to MCP servers that haven’t been vetted.
Sometimes it’s innocent (“this GitHub MCP server seems handy”). Sometimes it’s desperation (“we needed a quick connector”). Sometimes it’s experimentation that leaks into production.
Either way, shadow MCP becomes the agentic version of shadow SaaS—except now it can take actions, not just store data.
3. Tool sprawl: more tools = more confusion + bigger attack surface
Tooling teams love adding tools because each one solves a specific integration pain. Agents suffer when you do that too aggressively.
Too many tools increases ambiguity in what the agent should pick
It increases the number of “dangerous” edges (write/delete/admin actions)
It expands the context the agent needs to make good decisions
In practice, once you get past a certain number of tools, performance and reliability drop—and tets aren’t ready,” when the real issue is tool sprawl and taxonomy.
A practical heuristic I’ve seen hold up: once you’re above ~13 tools in a single agent’s working set, context and tool-selection quality often degrade unless you add strong tool routing and rationalization.
4. Post-incident forensics: can you reconstruct the chain?
When something breaks, you need an answer to a basic question:
What happened, in order, with evidence?
Forensics in agentic systems is harder because “the system” includes:
prompts and memory
tool calls
tool execution details
data access and changes
downstream side effects
If you can’t reconstruct the chain, you can’t do a real postmortem. You can’t prove compliance. And you can’t systematically improve.
This is the part that’s fundamentally different from agents in a lab.
5. The gateway gap: gateways see tool calls, not tool execution
A lot of teams’ first instinct is “put a gateway in front of MCP.” I get it. Gateways are a familiar control point.
But here’s the catch: MCP gateways tend to see tool calls, not what happens inside the tools—parameters, data flows, shelling out, subprocesses, and side effects.
Even worse: developers will bypass gateways if they add friction or latency, especially during fast iteration. route around constraints if the path of least resistance is available.
That doesn’t mean gateways are useless. It means they’re incomplete as the only control plane.
What “keeping agents on the rails” actually requires
I’ve become opinionated about the order of operations here, because I’ve watched teams try to jump straight to “control” before they have “visibiks like this:
1) Visibility across the full action path
Not just “tool called.” But:
tool called with parameters
tool executed what commands / queries
data touched, read/write boundaries
side effects and downstream calls
That’s what makes debugging possible, and it’s what makes governance real.
2) Safe experimentation environments (sandbox)
Teams need a place where agents can behave like interns—try things, make mistakes, learn—without risking production blast radius.
A sandbox is not just a testing environment. It’s a behavioral lab:
seeded data
constrained credentials
recorded traces
replayable tool chains
And crucially: you can test autonomy without betting the company.
3) Optional guardrails that don’t slow teams down
Guardrails shouldn’t be The best ones are:
optional (turn on when ready)
targeted (protect the risky edges)
mode-based (observe → warn → prevent)
And they should map to real failure modes: destructive tools, broad data access, privileged actions, uncontrolled code execution.
4) Dev + DevOps + Security working together
Agentic changes the collaboration model. Dev wants speedps wants reliability. In agentic systems, those goals converge on the same primitives: observability, controlled execution, and clear boundaries.
A good mantra here is the one I use internally:
Visibility first. Control when you’re ready.
How Teams Can Get Started (Practical Steps)
If you're building or deploying agents now, here's a pragmatic starting checklist, ordered by what to do first.
1. Pick your framework deliberately
Agent/orchestration frameworks are mainstream now (67% adoption in large enterprises). Choose one that supports tool management, tracing hooks, and structured policies. If your framework doesn't expose tool execution details, you're building on a blind spot.
2. Instrument for action-path visibility early
Don't wait for your first incident to discover you can't see tool execution. Make "I can trace what this agent actually did" part of your definition of done before you have 50 agents in production and no way to debug them.
3. Stand up a sandbox before agents hit prod
Teams need a place where agents can behave like interns: try things, make mistakes, learn, without production blast radius. A sandbox isn't just a test environment. It's a behavioral lab: seeded data, constrained credentials, recorded traces, replayable tool chains.
4. Treat agents like non-deterministic interns
This is the mental model I keep coming back to: agents can be brilliant and fast, and also weird and unpredictable. They need guardrails, not because they're "bad," but because autonomy without boundaries is how you get 3am pages.
5. Catalog and classify your MCP servers
For external MCP servers, decide what you trust before connecting. Build a list. Organize it by risk tier. Tools are emerging to help with this (MCP trust registries, security scanners). For internal MCP servers, the question shifts from "is it safe?" to "what can it do?" which leads to the next point.
6. Classify tools by blast radius
Some tools are read-only. Others are write, destructive, or admin-level. Know which is which, and make sure your agent knows too, via routing logic, explicit policies, or tool metadata. If you can't answer "what's the worst this tool can do?" you're not ready to give an agent access to it.
7. Rationalize tools to fight sprawl
If your agent has 30 tools, don't be surprised when quality drops. Large tool sets increase ambiguity (agent picks the wrong tool), expand attack surface, and blow out context windows. A practical heuristic: once you're past ~15 tools in a single agent's working set, add routing or hierarchies. Fewer tools, better decisions.
8. Bridge Dev + DevOps + Security now
Don't wait for a production incident to get these teams in the same room. The observability primitives that help developers debug are the same ones that help DevOps operate and Security govern. Align on shared tooling early. It's cheaper than aligning after a breach.
Platforms are being built to support this workflow (including ours at BlueRock), but the principles hold regardless of vendor: visibility first, control when you're ready, and never ship what you can't see.
Agents are accelerating—and the real power is still ahead
Wing’s data shows the agentic curve is bending toward production, yet we’re still in the early use cases—read-only, human-in-the-loop, narrow toolsets.
The real power of agentic comes when we enable actions and increase autonomy responsibly. That’s why these challenges need real work now. We should make agentic systems operable: observable, debuggable, governable, and safe enough to earn deeper trust over time.
Go fast. Stay safe.
I’d genuinely love to hear how your team is tackling this: What agentic or MCP challenges are you running into in the move from pilot to production?
FAQ
What is the “execution gap” in agentic AI systems?
The execution gap is the lack of visibility, control, and accountability between an agent’s tool call and the actual execution of code, data access, and side effects that occur inside tools and MCP servers.
Why do AI agent pilots fail to prepare teams for production?
Pilots usually involve read-only tools, limited data, and human oversight. Production agents operate autonomously, touch real systems, and take real actions—exposing gaps in observability, debugging, and governance.
How does MCP contribute to both progress and risk in agentic AI?
MCP standardizes agent-to-tool communication, making ecosystems easier to build and scale. At the same time, it accelerates exposure to risks like tool sprawl, shadow MCP servers, and hidden execution paths.
What do enterprises need to safely increase agent autonomy?
Enterprises need full action-path visibility, safe experimentation environments, gradual guardrails, clear tool blast-radius classification, and close collaboration between Dev, DevOps, and Security teams.
Why isn’t seeing MCP tool calls enough for security and operations?
Tool-call transcripts show intent, not execution. They don’t reveal subprocesses, shell commands, data sources, credential usage, or downstream side effects—making debugging, forensics, and compliance difficult.